Jump to section
- Machine Learning and Big Data in Manufacturing
- The Experiment: Anomaly Detection in CNC Data
- Graphing Feed Rate, Spindle Speed, and Parts Produced Over Time
- Feed Rate vs. Parts Made
- Enter, Machine Learning: Using Outlier Detection Algorithms to Find Anomalies
- Graphing the Outliers in Time to Reveal Root Causes
- Conclusions
Machine Learning and Big Data in Manufacturing
We often talk to manufacturers who are interested in applying machine learning algorithms to their manufacturing data.
As we’ve argued before, the key to success with ML and AI is robust data, which is why Tulip’s machine monitoring platform collects the data you need to truly understand your operations.
When it comes to big data analysis, our goal is to be an enabler. Tulip provides manufacturers with the data they need to apply the most sophisticated analysis techniques possible. We want to make it trivial for data science teams and engineers to collect in their job shops and extract data from Tulip so that they can unlock new levels of productivity and quality.
In this post, we’ll demonstrate how you can apply simple, powerful data science techniques to the data you collect with Tulip.
The Experiment: Anomaly Detection in CNC Data
In order to show how Tulip can empower data science initiatives, we conducted a quick experiment using data generated by a Tulip customer (anonymized here).
For the purposes of this experiment, we selected a data set collected by a customer using Tulip for machine monitoring. We picked this data set for several reasons.
First, the data set is large enough to properly train machine learning models. We pulled data from a 24-hour window, and the data set ran into the hundreds of thousands of rows. This is enough for most classifier, clustering, and anomaly detection algorithms to produce reliable results.
Second, the data set focused on the machine monitoring information that manufacturers care most about. From this data set we were able to graph critical KPIs like feed rate, spindle speed, and throughput–the basics you need for optimizing programs and calculating OEE. The data accounted for enough parameters to conduct an analysis relevant to activity on the shop floor, and consistent with the kinds of manufacturing analytics we see our customers use every day.
To conduct the analysis, we used popular python libraries like PANDAS and Sci Kit Learn in Jupyter Notebook. For data science teams, this same analysis is possible in whichever language you prefer, and can be performed in Microsoft Azure’s Data Studio, AWS’s SageMaker, or any analysis environment you use in your operations.
Pulling the Data
Pulling the data from Tulip was easy. The data was stored in no code tables that contained the exact parameters we needed.
Getting started was as simple as downloading a CSV, importing it into our notebook, and creating a data frame. It took 5 minutes and two lines of code.
What does AI-enabled quality inspection look like with Tulip?
Integrate machine learning-powered defect detection into your operator workflows with off-the-shelf cameras and no-code configuration.
Graphing Feed Rate, Spindle Speed, and Parts Produced Over Time
The next step after organizing the .csv file in data frames was to create graphs to visualize what was happening on the shop floor.
To start, we created a graph mapping three critical pieces of production data against one another: spindle speed, feed rate, and parts produced over time.
These three metrics are critical for optimizing production and ensuring asset health in the long term. Given that two identical machines running the same program in the same factory might have significantly different OEE, it’s important to measure exactly what happens during a production run.

This graph provides a good overview of production during this 24-hour window (the lines are fairly jagged because we used a relatively low sample rate of 20 minutes; faster sample rates produced noisy graphs). For the most part, it shows what you would expect from machine data. At almost all points, there’s a strong correlation between a spindle speed and feed rate, between spindlespeed:feedrate and parts produced.
Yet there are also some points where feed rate is inversely related with parts produced while spindle speed stays the same. There are even two instances where spindle speed and feed rate are zero, yet there are still parts produced.
Ultimately, this graph begs more questions than it answers. But it does its work. It prompts areas for further investigation, and makes it possible to drill down deeper into the data.
Feed Rate vs. Parts Made
The previous graph alerted us to the fact that feed rate was not always correlated with parts produced. The next step was thus to graph parts made against feed rate to better understand that relationship.

In this graph, we can see that parts made begins to rise precipitously when feed rate reaches 1400. The number of parts made continues to increase as feed rate approaches 1600.
What this graph reveals visually (that parts made seems to cluster between 5 and 10 at a feed rate of roughly 1600, could be borne out by further analysis. (Or, if you used data for this program collected over the course of many days, you could use linear regressions to predict the parts produced at a given feed rate for better line balancing).
Nothing in this graph is surprising. Which is good. That means, however, that we need to drill down further to better understand what’s happening on the shop floor.
Enter, Machine Learning: Using Outlier Detection Algorithms to Find Anomalies
The next step was to graph spindle speed against feed rate. Doing so allowed us to understand exactly what settings are correlated with the highest throughput.

Across the production day, high spindle speeds are highly correlated with high feed rates. Again, this is to be expected.
But we did notice several points that did not conform to these patterns. The question we asked at this point is, “to what extent are there statistical outliers in this graph?”
The answer to this question is important for two reasons. For one, those outliers could reveal behavior or processes on the shop floor that directly impact production. Locating and understanding these data points, in other words, can directly translate into higher productivity. Second, outliers can hurt the performance of many machine learning algorithms. So determining whether we need to exclude these points from our analysis is critical to returning accurate insights.
To determine whether our data set included outliers, we used a method called Isolation Forest (you can read more about this technique here).
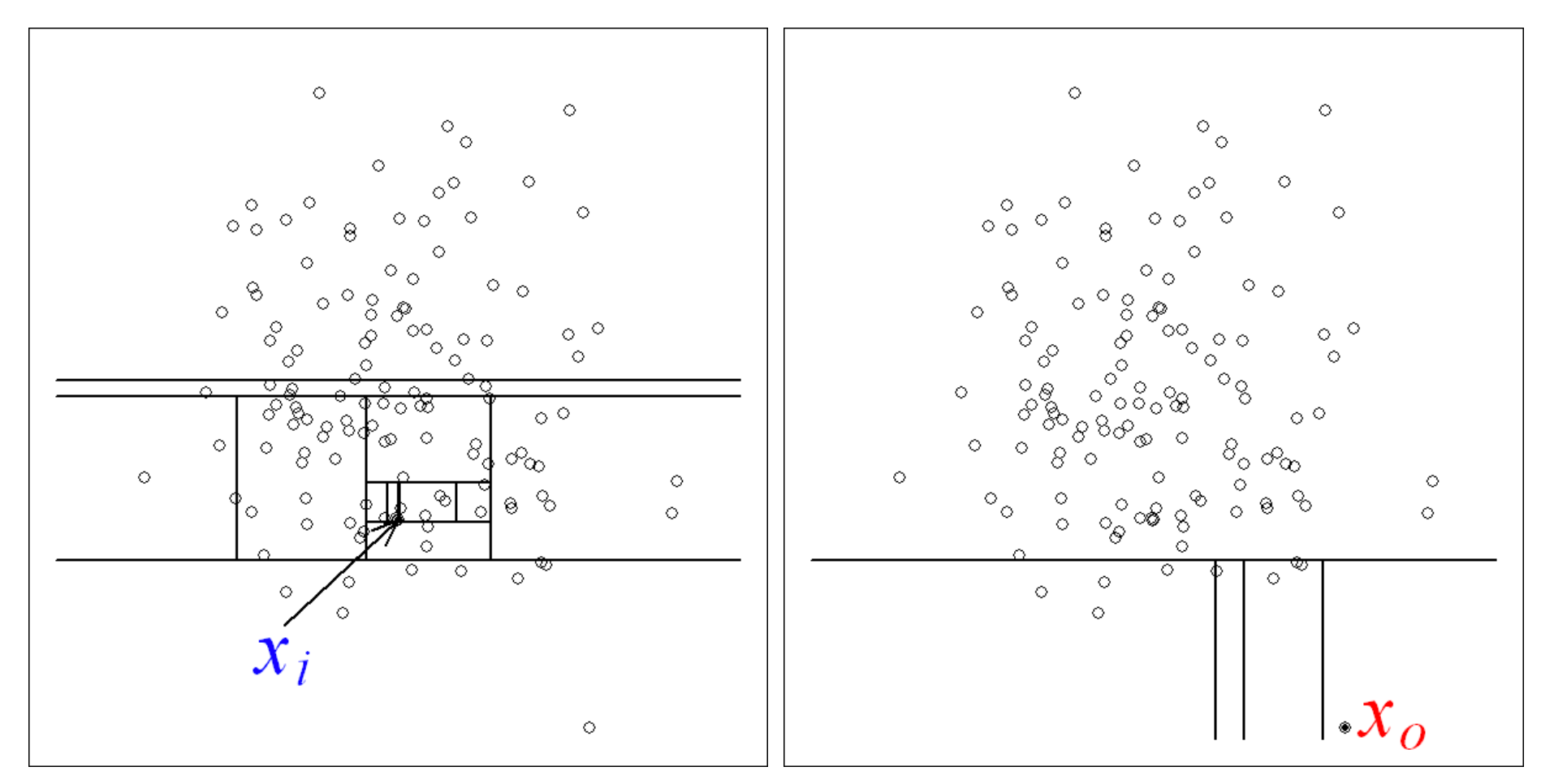
The Isolation Forest located 5 data points it considered to be outliers.
Not only does this give us a cleaner data set, but it lets us ask a critical question: what was happening with those machines at those points?
Graphing the Outliers in Time to Reveal Root Causes
The final step in this experiment was to map our anomalies back onto our initial graph of the production day.
Let’s look first at the three lines that occur just after 03:00. If we check this against our initial graph (feed rate, spindle speed, parts produced over time), we see that all three of these outliers coincide with a precipitous drop in all three metrics.
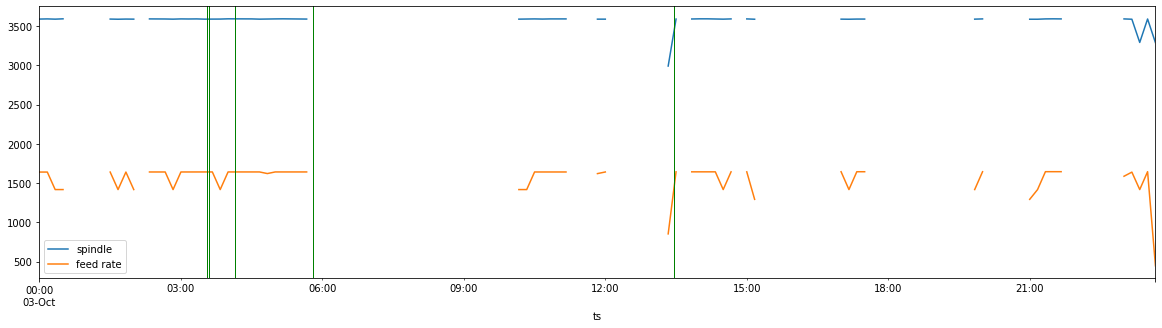
The question becomes: what happened then? Importantly, graphing these events in this fashion lets us ask more informed questions. Who was the operator? Which program was running? What were the conditions in the factory? Who was the shift supervisor? Was a changeover performed correctly? Was the right tool available? Was there a mechanical problem?
These are some of the many questions that manufacturers need to answer on a daily basis to make their operations as profitable as possible.
Further, with Tulip’s machine monitoring, you need not limit your analysis to these three variables. With Tulip, you can track other parameters that will add nuance and perspective to these common parameters.
Conclusions
This analysis is simplistic. There’s no reason to pretend otherwise.
But by running simple machine learning analyses on your machine monitoring data, you determine which questions are the best to ask at any given moment.
This is the real value of augmenting machine monitoring with machine learning. The algorithms can help you find order in massive data sets. But ultimately they give engineers and opportunity to isolate and solve difficult manufacturing problems in less time and with more certainty than ever before.
To conclude, there’s a point we’d like to emphasize.
We were able to put this analysis together in a few hours. Because Tulip tables collects and organizes data in an accessible fashion there was no need to create tables with SQL, and we didn’t need to spend much time doing the painstaking work of feature engineering.
This kind of analysis doesn’t require a master’s degree in data science or expensive software. One of our engineers put it together in a few hours using industry standard, publically available analysis libraries. A team of business and analysts and data scientists working with customized data sets collected by Tulip could go much further in the same time.
What we intended here was not to produce a definitive analysis, but rather to show how easy it is to create insights that make a difference.